Welcome back to my series of posts on the recipe-management software I’m building. If you haven’t been following along, you’ll probably want to start at the first post. This isn’t so much a tutorial series like my posts on raytracing, just me writing about whatever’s on my mind as I build out my vision of what a recipe manager should be.
Progress
In the last post I finished building the ingredient editor, meaning that I could move on to the recipe editor - probably the most important view in the whole application. Since then, I’ve completed the recipe editor and moved on to start working on a page for searching and filtering the recipes.
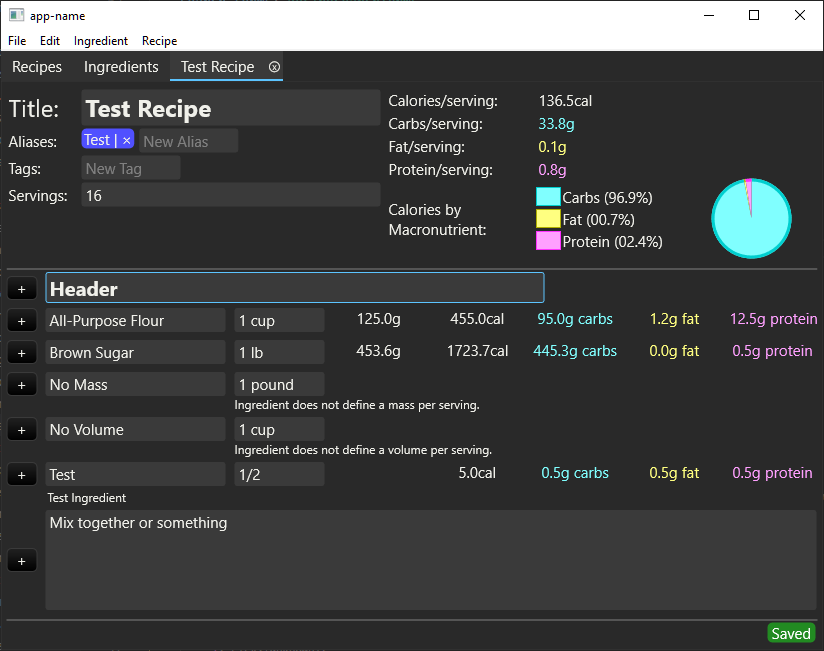
A lot of progress has happened in the last two weeks! First up, the recipe editor. It shows all of the recipe-level nutritional information and metadata at the top of the screen. The really cool part is the UI for editing the recipes themselves though. The user can insert ingredients, headers and instructions in any order. You can add, delete, or reorder recipe components using the button on the left, the Recipe menu at the top, or keyboard shortcuts. To minimize the friction of adding components, the keyboard focus is automatically placed exactly where the user will probably want it - in the main textbox of the new component.
The ingredient box is free-form text; beneath it the tool displays its best guess at which ingredient you meant (which includes aliases) but to save space it only shows that if it doesn’t match what you typed. Pressing enter in the ingredient box auto-completes the text box with the best-guess ingredient. Hitting enter in the amount box will auto-complete with whatever the tool’s best guess at which ingredient you wanted as well, so you can enter ingredients quickly directly from the keyboard - “1 pound of butter” might be “b-u-t-<enter>-<tab>-1-p-o-u-<enter>“. It’s not quite as good as a real autocomplete dropdown - the user can’t use the arrow keys to select the second or third guess - but it seems to work just fine so far. I’m sure in the future Druid will make it easier to build a real autocomplete dropdown, and I’ll update my code to do that instead.
As discussed in earlier posts, I prefer to measure things by mass when I can, so the recipe editor automatically calculates the mass in grams of all ingredients wherever possible. It also gives clear error messages when the user tries to specify a mass or volume but the ingredient doesn’t specify the mass or volume of a serving.
Not only is it delightfully low-friction to use, but I like having the ability to separate out logical groupings of ingredients and the instructions that go with them. A lot of recipes come in the form of a big list of ingredients and then a big list of instructions, but that just seems like a poor way to structure recipes to me. This system can handle recipes like that, if that’s what the user wants, but it also allows them to create logical groupings to make reading and following the recipe easier.
One thing that I haven’t done (yet) is allow the ingredient box to auto-complete to other recipes. Especially in the world of baking, there are a lot of recipes for things that are then used in other recipes. Creme Patisserie (AKA pastry cream) is a kind of pudding often used for filling in things like cakes or cream puffs. Whip it together with butter and you get German Buttercream, a tasty cake frosting. Alternately, whip it with whipped cream and you get Creme Diplomat. One might have one or two standard recipes for Creme Patisserie and use them transitively in a bunch of different recipes. An analog for the savory cooking world might be the French mother sauces. Of the two apps I currently use, one simply does not allow this and the other requires a weird workaround. If I update my standard recipe for one of these reusable components, I want the resulting change in nutritional information to be automatically propagated to the recipes that use it. I will need to be careful to handle self-recursive recipes without an infinite loop - right now I’m leaning towards allowing self-recursive recipes, but making it so the self-recursive components have no nutritional information. Recipes which contain themselves do exist, but they’re rare. One example is confectioners’ fondant - a crystallized sugar syrup used in making chocolates (no, it’s not the same stuff they make pretty-but-tasteless cakes out of). It’s common for a bit of the last batch of fondant to be added to a new batch as a seed to speed up the crystallization process. I figure if you add 100g of fondant to the mixer, then take out 100g of the finished fondant and freeze it for next time, there should be no net effect on the overall nutritional contents.
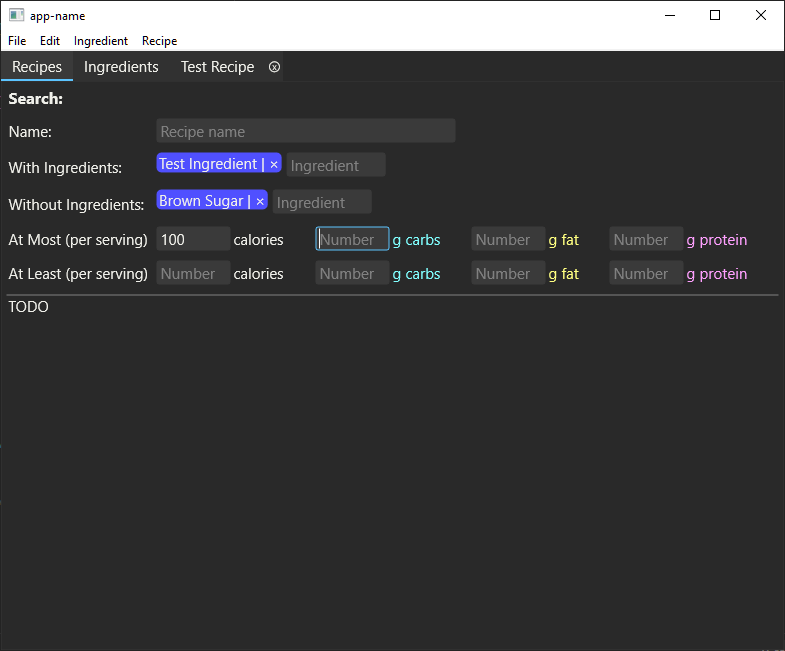
I’ve also started building out the recipe search page. This is what I’ll use when I’m deciding what I want to cook. I haven’t actually built the searching logic yet, but I’ve laid out the search form. It will take some experience with using it to be sure, but these seem like the right search criteria. One thing to note is that I’ve enhanced the “bubble list” widget to allow for autocompletion there as well, so you can hit “b-r-<enter>” and it will add “Brown Sugar” to the list.
Filtering recipes by their nutritional content is one of those features that I’ve wanted for a long time but it seems like nobody else has ever thought of. Certainly neither of the apps that I’m looking to replace provides this feature. It seems like such an obvious thing - “I have 453 calories left for today, what can I make?” is the sort of question I ask fairly often, why not have the computer assist me in answering it?
Although, I’ve only just noticed that I don’t have a field for tags here. Will have to add that.
I’m also trying to establish a consistent color scheme for carbs/fat/protein. I don’t know how useful that will be, but it seems to help with readability at-a-glance. They’re also always displayed in the same order.
Data Integrity
One of the downsides of storing everything in text files rather than a mature database is that now I have to be more responsible for maintaining the integrity of the data. I can’t set up foreign keys or constraints to automatically enforce that everything is self-consistent. I fully expect this to be the source of a lot of ongoing weird bugs and potentially data loss. This is starting to become more relevant as I work on building recipe features - unlike ingredients, recipes aren’t just a collection of independent records. They refer to ingredients and (as discussed above) other recipes, and might need to be updated if those recipes change.
I think I’ve come up with a way to mitigate this problem somewhat. In short, I intend to just not store anything but the most minimal possible representation necessary to reconstruct what the user meant.
Allow me to explain in more detail. My thinking on this is influenced by this video, about data redundancy bugs in classic video games. To summarize, a lot of famous bugs in classic games (such as the save-corruption glitch that allows for arbitrary code execution in Pokemon Red & Blue) came about because the developers cached some important property such as the length of a sentinel-terminated list rather than re-deriving it from the list each time it was needed. This saves CPU cycles - which is important on a system as limited as the Game Boy - but it means that if the cached length of the player’s item list ever disagrees with the actual length of that list, there are bugs.
On old video-game systems, this was almost a necessary trade-off - the CPUs of those systems were so underpowered that recalculating everything all the time would have made the games unacceptably slow. We have much faster computers these days, though, and I have plenty of room to spend time computing things without noticeably impacting the user’s flow.
I realized that I had essentially the same problem - if I saved the nutritional breakdown of every ingredient in a recipe to disk, that could get out of sync with changes to the ingredient itself. Then what? I could recompute the nutrition when the user loads the recipe, but then what was the point of saving it? I could eagerly update all recipes that contain an ingredient each time an ingredient is saved, but what if the user edits an ingredient file with a text editor?
So what I’m going to do instead is store only the text the user typed in for the ingredient and amount (which I have to store anyway because I don’t want the software to change what I wrote), plus the ingredient ID that matched to. I don’t store anything else about the ingredient or the amount in the recipe files. This does mean that when the software needs to determine the nutritional content of a recipe there will have to be a recursive process of resolving the nutrition of every ingredient. It will also have to re-parse the amount of each ingredient the recipe calls for by parsing the amount string. Doing it this way ensures that everything is always exactly up to date.
It might seem strange that I save the ingredient string and the matching ingredient ID, but only save the amount as a string. This is a bit of a judgement call - mainly I’m doing that because the amount parsing shouldn’t change significantly, so I expect that any amount I care about will parse to the same value later as it did when I saved it. In fact, I actually want it to be recomputed - if I specify that a recipe contains 100g of peanut butter, and then switch to a different brand of peanut butter that 100g might now be a different number of servings, and so the number of servings should be recomputed from the updated ingredient and the text of the amount field. On the other hand, adding or renaming an ingredient could cause the fuzzy-matching to pick a totally different closest-match than what it did when I wrote the recipe to start with, which I don’t want.
Every ingredient and recipe (and anything else I add to the system in the future) has a random UUID as a unique identifier. It’s not perfect, though. For example, the user might copy a recipe file in the file system and not change the UUID. Probably the best thing I can do to deal with this sort of edge-case scenario is to detect it at startup and flag an error for the user to fix. Once I get around to integrating a Git repository for the data into the software itself, though, it would be possible to detect those sorts of changes and decide how best to resolve them.
Doing this well does take some degree of domain knowledge though. For example, when I get around to implementing a daily calorie/macronutrient counter, I do intend to store the nutritional information in those records. The difference is that those are historical information - if for some reason I look back at what I ate six months ago, I want to see the nutritional information for precisely what I made back then, even if I’ve changed the recipes or ingredient data since then. When I’m looking at the recipes themselves, I’m interested in what they would contain if I made them now.
A Bit More Druid
Last post I mentioned that I’d changed my mind on how intrusive Druid widgets should be into the application’s data model. That process has continued, and I’m now settling on “very intrusive indeed”. I’m coming to the conclusion that basically anything the user can change should be a part of the application model.
I’ve been continuing to expand my collection of custom widgets, and one pattern that I’ve found to be useful is for a complex widget like my ersatz autocomplete-text-box to expose its own state struct and require that the application model contain one of those. For the autocomplete box, that struct includes the string the user typed in as well as the completed value. That way, when the user loads a recipe the software can populate the autocomplete state with both the saved text and the selected ingredient ID.
Widgets which don’t expose their user-editable state to the application model are forced to provide a more complicated Command-based interface to detect changes to it or allow the application to set it.
Of particular note is the built-in Tabs widget, which does not expose the currently-selected tab. It also does not have the aforementioned Command-based interface, which means that it is currently impossible for the application to react to the user changing the current tab, or to switch tabs itself. I can’t, for example, open a new tab and switch to it immediately, or automatically save the data in a tab when the user switches to another.
As I develop this recipe manager, I keep running into cases where I wrote a custom widget to hide its state from the application and then regretted it and had to do more work to expose it again. I’m starting to learn from my mistakes and just expose that state from the start.
Conclusion
Well, that’s about it for now. Over the next couple weeks I’ll probably aim to finish up the recipe search.
I’ll admit that I’ve maybe been working harder on this and for longer than is really a good idea. The way I usually do hobby-project work (at least when it comes to software) is to work on it intensely for a relatively short period of time. This one is coming up on two months so far, so it’s not that short. I don’t really recommend this approach, but it’s what I usually fall into doing anyway. So I’m aiming to reach a point where it’s minimally usable so I can call it good and set it aside for a while. I still have a lot more ideas for features I want to add, but those will have to wait.
(Incidentally, this is why Criterion-rs tends to see short periods of intense work followed by months of total neglect.)
Hopefully I’ll be able to wrap this up by the Christmas holidays and then take some time to do other things (like actually do some cooking) before picking it up again in the new year.